What would it take to recreate dplyr in python? | Michael Chow
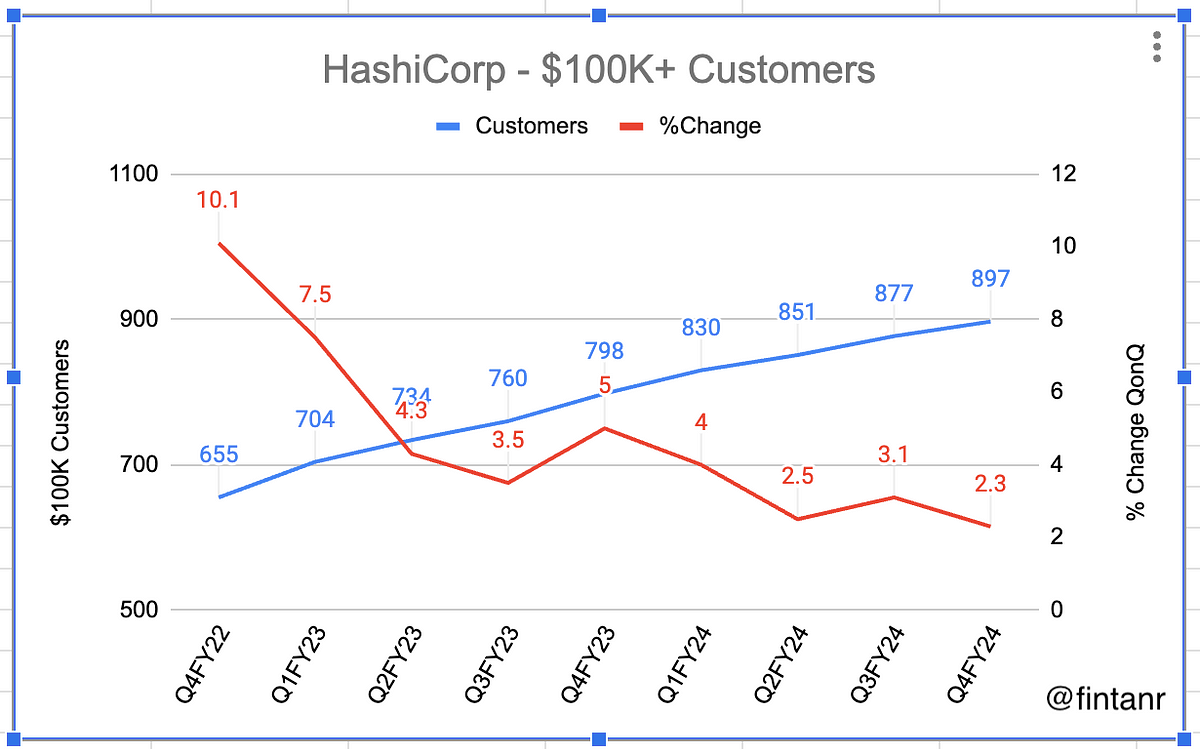
In order to do the second part, I’ve worked over the past year on a data analysis library called siuba. As part of this work, I’ve found myself often discussing siuba’s hardest job: making grouped operations a delight.
In this post I’ll provide a high-level overview of three key challenges for porting dplyr to python. Because the pandas library is the most popular python implementation of both a DataFrame AND performing split-apply-combine on it, I’ll focus mostly on the challenges of building dplyr on top of pandas. Note that all of these challenges arise during the process of split-apply-combine.
However, similar expressions in grouped pandas either run very slowly (e.g. 30 seconds for only 50k groups), or require cumbersome syntax. In the following sections, I’ll break down how the index and type conversion taxes make custom functions slow, examine complex expressions in pandas, and finally highlight experimental work with siuba to bridge the gap.
Before starting it’s worth noting that I feel tremendous appreciation for the pandas library, the many challenging problems it tackles, and the time people contribute to it.
Leave a Comment






Recent Posts



Asian American women are getting lung cancer despite never smoking. It’s baffling scientists and leading to more research.
Comment