What's new in pgvector v0.7.0
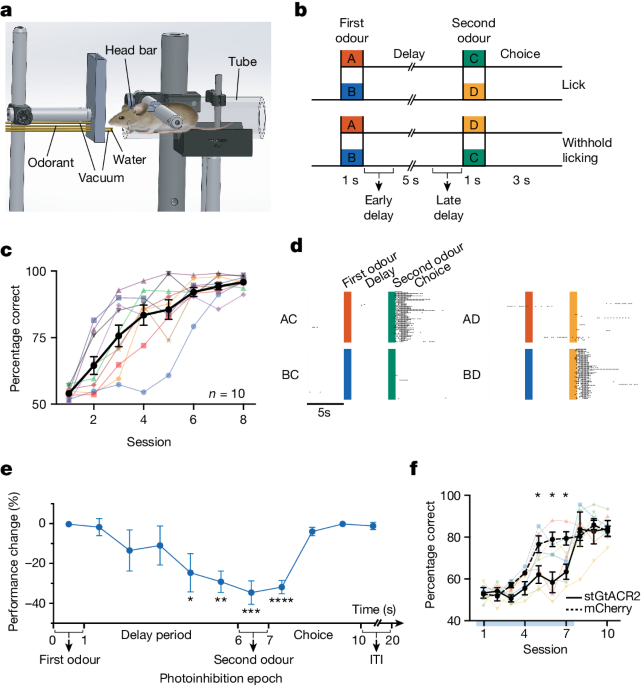
Real-world embedding datasets often contain redundancy buried within the vector space. For example, when vectors cluster around certain central points in a multidimensional space, it reveals an exploitable structure. By reducing this redundancy, we can achieve memory and performance savings with a minimal impact on precision. Several approaches to leverage this idea have been introduced in pgvector since version 0.7.0:
An HNSW index is most efficient when it fits into shared memory and avoids being evicted due to concurrent operations, which Postgres performs to minimize costly I/O operations. Historically, pgvector supported only 32-bit vectors. In version 0.7.0, pgvector introduces 16-bit float HNSW indexes which consume exactly half the memory. That reduction in memory keeps operations at maximum performance for twice as long.
HNSW build times recently experienced a stepwise improvement in the 0.6.2 release, which introduced parallel builds. 0.7.0 with the halfvec (float16) feature improves that speedup a further 30%.