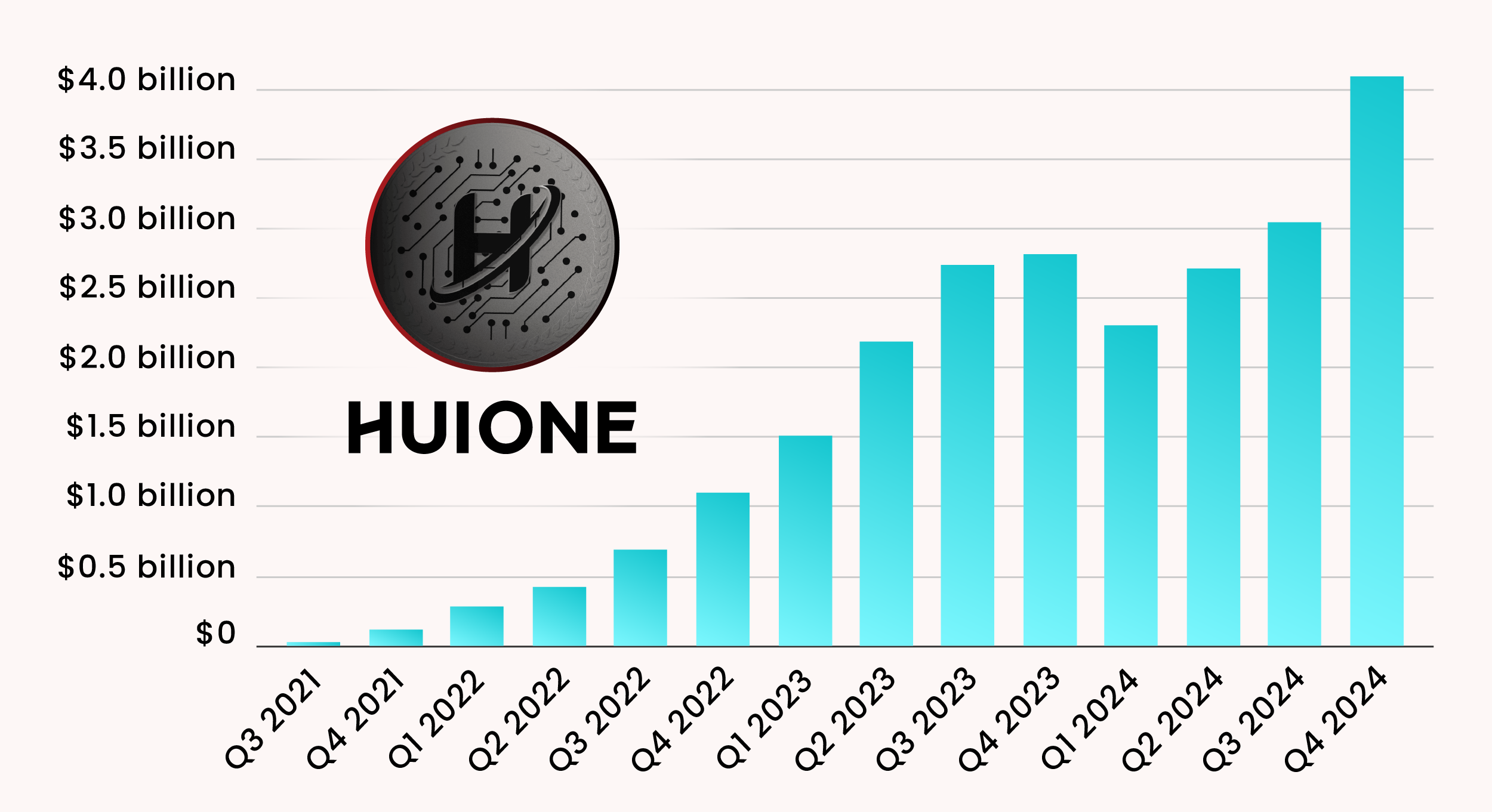
Drone-assisted Road Gaussian Splatting with Cross-view Uncertainty
Qualitative results of our Drone-assisted Road Gaussian Splatting with Cross-view Uncertainty and several baseline methods.
Robust and realistic rendering for large-scale road scenes is essential in autonomous driving simulation. Recently, 3D Gaussian Splatting (3D-GS) has made groundbreaking progress in neural rendering, but the general fidelity of large-scale road scene renderings is often limited by the input imagery, which usually has a narrow field of view and focuses mainly on the street-level local area. Intuitively, the data from the drone's perspective can provide a complementary viewpoint for the data from the ground vehicle's perspective, enhancing the completeness of scene reconstruction and rendering. However, training naively with aerial and ground images, which exhibit large view disparity, poses a significant convergence challenge for 3D-GS, and does not demonstrate remarkable improvements in performance on road views. In order to enhance the novel view synthesis of road views and to effectively use the aerial information, we design an uncertainty-aware training method that allows aerial images to assist in the synthesis of areas where ground images have poor learning outcomes instead of weighting all pixels equally in 3D-GS training like prior work did. We are the first to introduce the cross-view uncertainty to 3D-GS by matching the car-view ensemble-based rendering uncertainty to aerial images, weighting the contribution of each pixel to the training process. Additionally, to systematically quantify evaluation metrics, we assemble a high-quality synthesized dataset comprising both aerial and ground images for road scenes. Through comprehensive results, we show that: (1) Jointly training aerial and ground images helps improve representation ability of 3D-GS when test views are shifted and rotated, but performs poorly on held-out road view test. (2) Our method reduces the weakness of the joint training, and out-performs other baselines quantitatively on both held-out tests and scenes involving view shifting and rotation on our datasets. (3) Qualitatively, our method shows great improvements in the rendering of road scene details.
Results for training with ground or aerial and ground images on various models. (G), (A+G) are training with ground or aerial and ground images. Incorporating aerial images helps to mitigate the decline in metrics of the road view synthesis after the view shifting and rotation compared with merely using ground data. However, aerial images do not enhance the result on the held-out test of road scene synthesis.

/cloudfront-us-east-2.images.arcpublishing.com/reuters/IUIUQZBMY5LZTBRO6IIF2Z4DH4.jpg)







/cdn.vox-cdn.com/uploads/chorus_asset/file/25831586/STKB310_REDNOTE_XIAOHONGSHU_B.jpg)