OpenAI's new open-source model is basically Phi-5
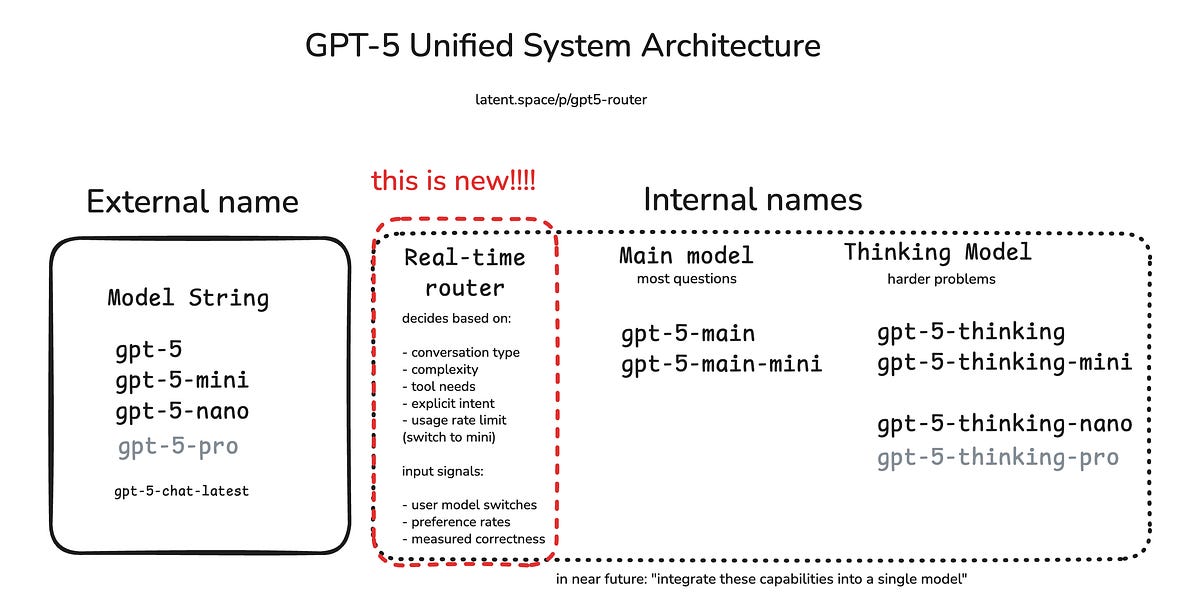
OpenAI just released its first ever open-source1 large language models, called gpt-oss-120b and gpt-oss-20b. You can talk to them here. Are they good models? Well, that depends on what you’re looking for. They’re great at some benchmarks, of course (OpenAI would never have released them otherwise) but weirdly bad at others, like SimpleQA.
Some people really like them. Others on Twitter really don’t. From what I can tell, they’re technically competent but lack a lot of out-of-domain knowledge: for instance, they have broad general knowledge about science, but don’t know much about popular culture. We’ll know in six months how useful these models are in practice, but my prediction is that these models will end up in the category of “performs much better on benchmarks than on real-world tasks”.
In 2024, Sebastien Bubeck led the development of Microsoft’s open-source Phi-series of models2. The big idea behind those models was to train exclusively on synthetic data: instead of text pulled from books or the internet, text generated by other language models or hand-curated textbooks. Synthetic data is less common than normal data, since instead of just downloading terabytes of it for free you have to spend money to generate each token. But the trade-off is that you have complete control over your training data. What happens when you train a model on entirely high-quality synthetic and curated data?