The Stanford AI Lab Blog
Take a look at the video above and the associated question – What did they hold before opening the closet?. After looking at the video, you can easily answer that the person is holding a phone. People have a remarkable ability to comprehend visual events in new videos and to answer questions about that video. We can decompose visual events and actions into individual interactions between the person and other objects . For instance, the person initially holds a phone and then opens the closet and takes out a picture . To answer this question, we need to recognize the action “opening the closet ” and then understand how “before ” should restrict our search for the answer to events before this action. Next, we need to detect the interaction “holding ” and identify the object being held as a “phone ” to finally arrive at the answer. We understand questions as a composition of individual reasoning steps and videos as a composition of individual interactions over time.
Designing machines that can similarly exhibit compositional understanding of visual events has been a core goal of the computer vision community. To measure progress towards this goal, the community has released numerous video question answering benchmarks (TGIF-QA, MSVD/MSRVTT, CLEVRER, ActivityNet-QA). These benchmarks evaluate models by asking questions about videos and measure the models’ answer accuracy. Over the last few years, model performance on such benchmarks have been encouraging:
Leave a Comment
Related Posts









Recent Posts







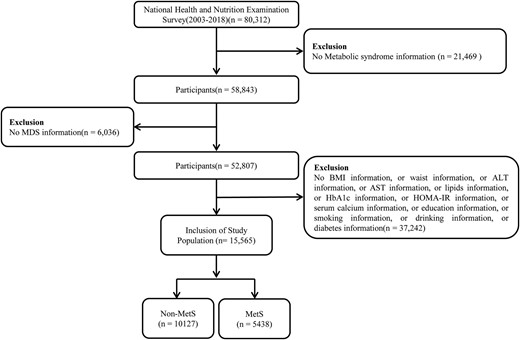
Magnesium Depletion Score and Metabolic Syndrome in US Adults: Analysis of NHANES 2003 to 2018
Comment