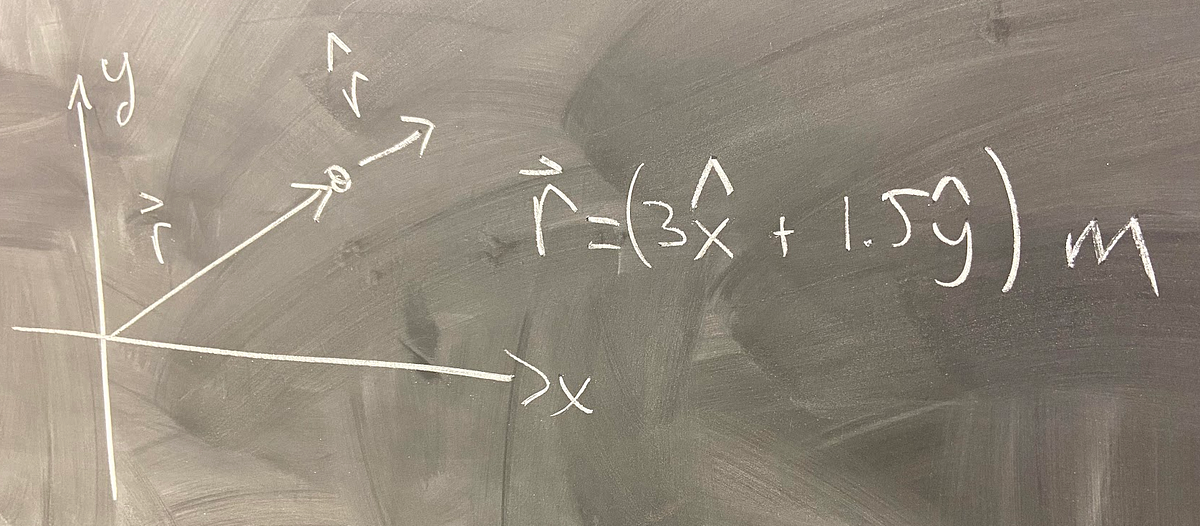An exploration of vector search
With the AI hype going around, you may have come across the phrase "vector search", "vector database", or "embeddings" lately. Here's an exploration of what that means. I'm not a data scientist, but I was intrigued and decided to dig in.
The idea behind vector search is: "What if we could represent the items in our database, as well as the input term, as vectors? We could then find the vectors which are closest to the input." Let's dig into that.
Think of a vector as describing a movement from one point in space to another point. For instance, in the graph below, we can see some vectors in 2D space: a is a vector from (100, 50) to (-50, -50), and b is a vector from (0, 0) to (100, -50).
A lot of the time (and in the rest of this article), we deal with vectors starting from the origin (0, 0), such as b . We can then omit the "from" part, and simply say b is the vector (100, -50).
As we've seen, each numerical vector has x and y coordinates (or x, y, z in a 3D system, and so on). x, y, z... are the axes, or dimensions of this vector space. Given some non-numerical entities we want to represent as vectors, we need to first decide on the dimensions, and assign a value to each entity for each dimension.