
Local LLM-as-judge evaluation with lm-buddy, Prometheus and llamafile
In the bustling AI news cycle, where new models are unveiled at every turn, cost and evaluation don’t come up as frequently but are crucial to both developers and businesses in their use of AI systems. It is well known that LLMs are extremely costly to pre-train; but closed source LLMs such as OpenAI's are also very costly to use.
Evaluation is critical not only to understand how well a model works but also to understand which model works best for your scenario. Evaluating models can also be costly, especially when LLMs are actively used to evaluate other models as in the LLM-as-Judge case. And while techniques to scale inference could also be applied to LLM judges, there does not seem to be a lot of interest in this direction.
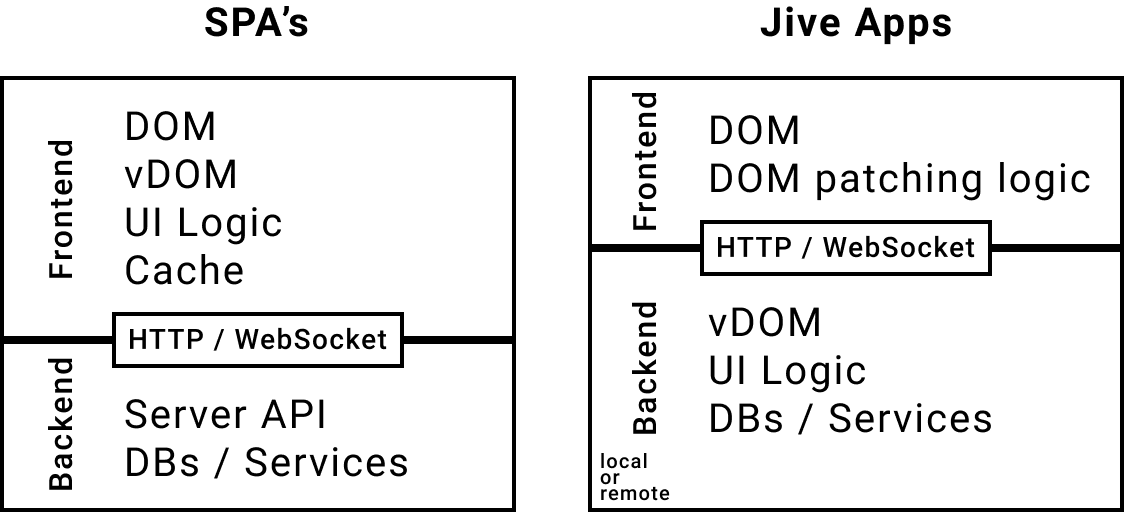
This post examines how different software components came together to allow LLM-as-judge evaluation without the need for expensive GPUs. All the components were built with and chosen for their user control, open source nature, and interoperability.
These include Prometheus, an open-source model for LLM-as-judge evaluation; lm-buddy, the tool we developed and open-sourced at mzai to scale our own fine-tuning and evaluation tasks; and llamafile, a Mozilla Innovation project that brings LLMs into single, portable files. I will show how these components can work together to evaluate LLMs on cheap(er) hardware, and how we assessed the evaluators’ performance to make informed choices about them.













:max_bytes(150000):strip_icc()/__opt__aboutcom__coeus__resources__content_migration__treehugger__images__2018__03__IMG_1257-41a4598fa66f4e0aa5749da8af60ed66.jpg)

