Explained from scratch: private information retrieval using homomorphic encryption
This is a from-scratch explanation of private information retrieval built using homomorphic encryption. I try to assume only a general math / computer science background. To simplify things, my explanations may not always match academic definitions. You can check out this Wikipedia demo, Bitcoin balance checker, paper, or code for more. Follow us @SpiralPrivacy.
A naive solution is to download and store the entirety of Wikipedia; then, all your queries can be local and the server never learns anything. Unfortunately, this takes a lot of bandwidth and storage (~10 GB), so it isn’t very practical.
Another strawman solution might be to put the articles in buckets, and just send some ‘dummy’ articles along with the true response. This still leaks significant information - over time, or with any additional prior about your behavior, it’s easy to narrow down the set of articles you were really looking at.
It turns out that we can do much better - it is possible to cryptographically guarantee that the server cannot learn anything about your query. In cryptography, this problem is called “Private Information Retrieval”, or “PIR”. In PIR, a client wishes to retrieve the $i$-th item of an $n$-item database hosted on a server, without revealing $i$ to the server or downloading the entire database. Crucially, this “query privacy” guarantee should hold even if the server is actively malicious.
Leave a Comment








Recent Posts


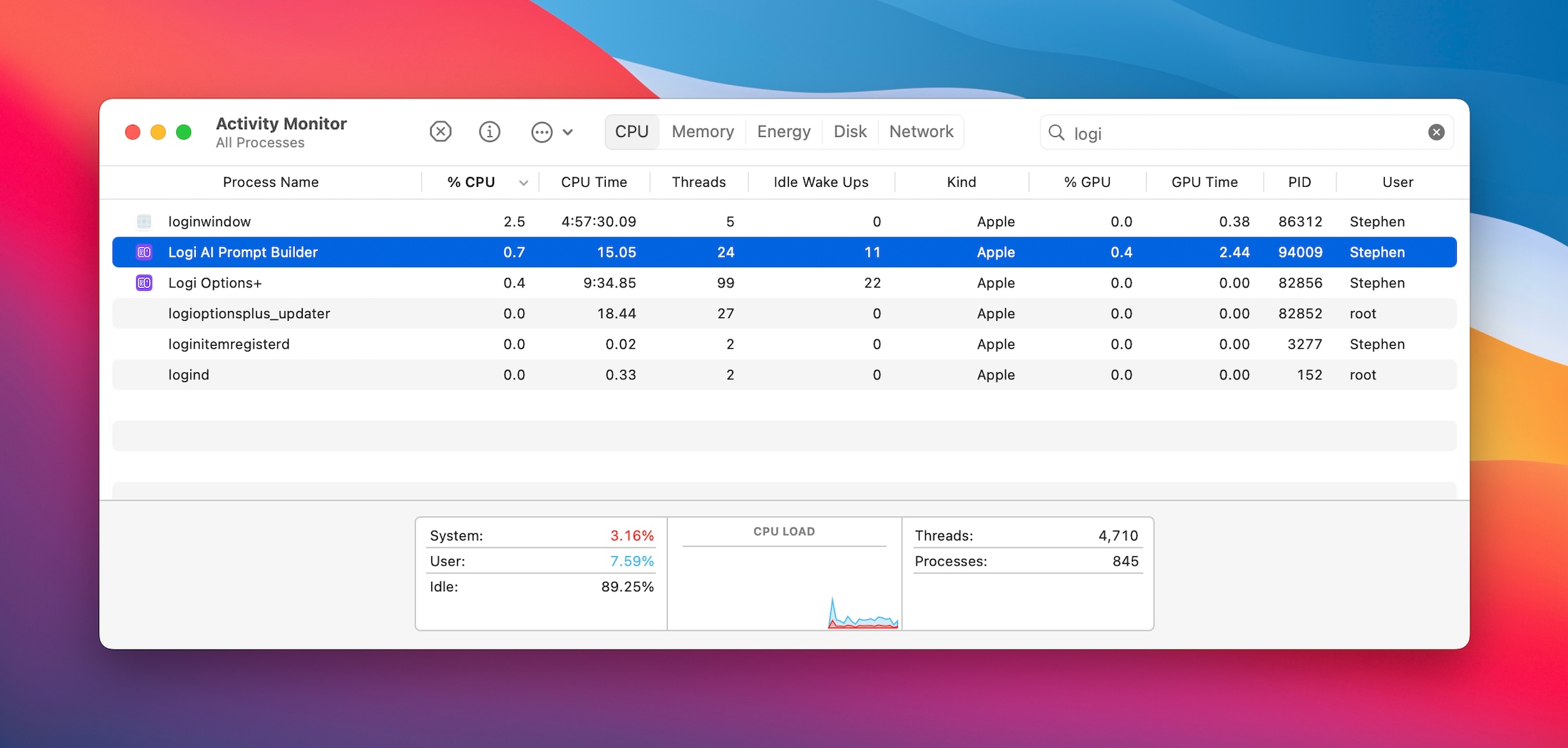
Logitech’s Mouse Software Now Includes ChatGPT Support, Adds Janky ‘ai_overlay_tmp’ Directory to Users’ Home Folders
Comment

/cloudfront-us-east-1.images.arcpublishing.com/pmn/2OMDYOYIKRDYJOSDNJCST4GN34.jpg)








