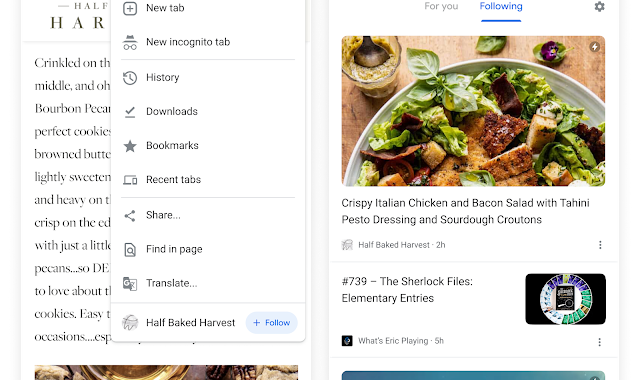
A deeper dive into Chrome WebFeed
You should first read about the article Chrome experiment to let you Follow websites before you keep reading this one. This article goes deeper into the technical details of how Chrome WebFeed works.
Chrome detects all Atom and RSS feeds on webpages using the feed auto-discovery mechanism. Here’s a quick refresher if you’re unfamiliar or have forgotten it in the last decade:
When any feeds are detected on a page, Chrome sends the feed addresses and page address to a Google server. This server then tells Chrome which of the feeds Google recommends and whether that feed is actively updated. Chrome uses this information to decide on whether to prompt the user to follow the website.
Chrome also receives the site’s name for use in user interfaces related to feed management from Google’s servers. It uses the site’s domain name as a fallback. Chrome will also try to detect the largest icon from the page (<link rel="icon" […]>) instead of using icons specified in the feed. Chrome never actually downloads the feed locally.
The client-side implementation is open-source and available to other Chromium-based web browsers such as Brave, Microsoft Edge, and Vivaldi. However, don’t expect any of the other browsers to introduce a feed aggregator in a future release. They’d have to invest in and reimplement the server-side component that makes WebFeed work. Brave and Edge already have their own news feed systems and are unlikely to build on Chrome’s implementation. Brave is notably working on support for adding custom syndication feeds, but it requires manual entry of feed addresses (with all the usability issues that entail.)
/https://public-media.si-cdn.com/filer/9f/61/9f610676-9962-4627-ae89-bf59fc6cb735/lod_mosaic_lower_register_web.jpg)






/cdn.vox-cdn.com/uploads/chorus_asset/file/23935561/acastro_STK103__04.jpg)
/cdn.vox-cdn.com/uploads/chorus_asset/file/24371483/236494_Mac_mini__2023__AKrales_0066.jpg)