
Visual Language Models on NVIDIA Hardware with VILA
Visual language models have evolved significantly recently. However, the existing technology typically only supports one single image. They cannot reason among multiple images, support in context learning or understand videos. Also, they don’t optimize for inference speed.
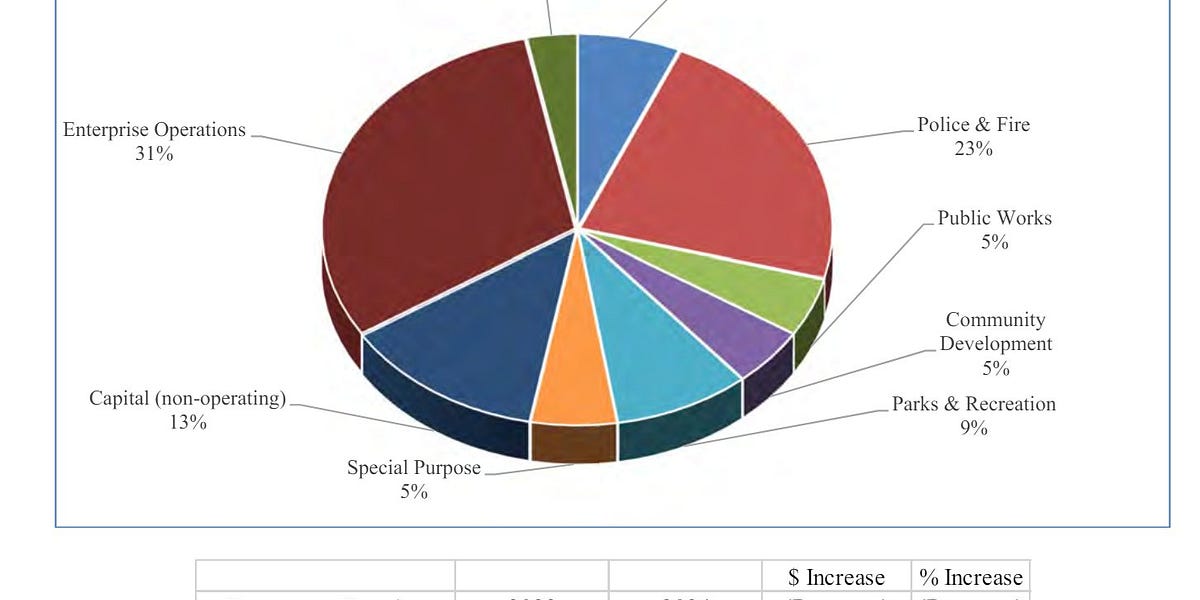
We developed VILA, a visual language model with a holistic pretraining, instruction tuning, and deployment pipeline that helps our NVIDIA clients succeed in their multi-modal products. VILA achieves SOTA performance both on image QA benchmarks and video QA benchmarks, having strong multi-image reasoning capabilities and in-context learning capabilities. It is also optimized for speed.
It uses 1 ⁄ 4 of the tokens compared to other VLMs and is quantized with 4-bit AWQ without losing accuracy. VILA has multiple sizes ranging from 40B, which can support the highest performance, to 3.5B, which can be deployed on edge devices such as NVIDIA Jetson Orin.
We designed an efficient training pipeline that trained VILA-13B on 128 NVIDIA A100 GPUs in only two days. In addition to this research prototype, we demonstrated that VILA is scalable with more data and GPU hours.













/https%3A%2F%2Ftf-cmsv2-smithsonianmag-media.s3.amazonaws.com%2Ffiler_public%2F73%2F5c%2F735ce030-bc9a-4925-a4da-4eaa225bc873%2Fgettyimages-1413268947.jpg)

