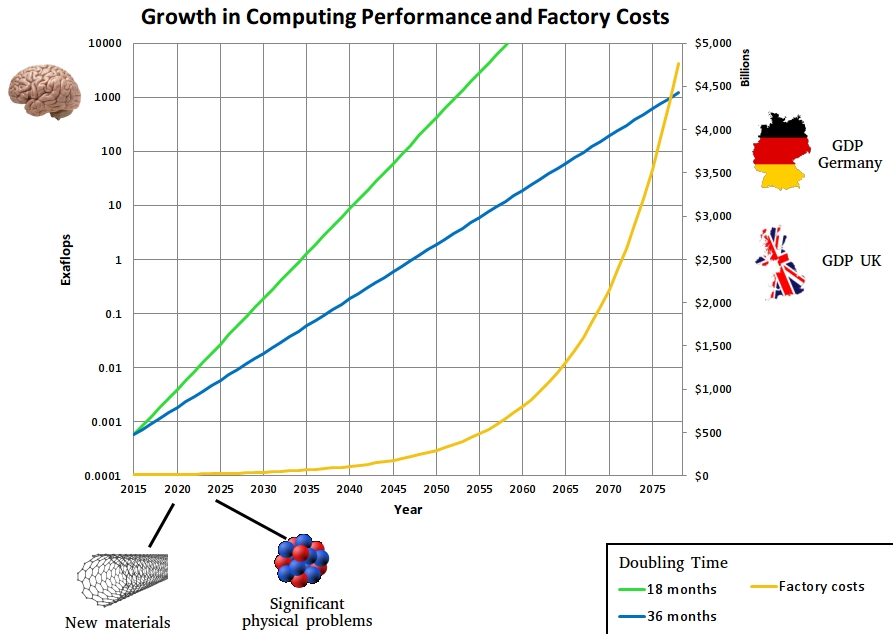
Some More Weird Tricks to Shrink Convolutional Networks for TinyML
A few days ago, Pete Warden, whose work inspired me to get into tinyML, released a blog titled “One weird trick to shrink convolutional networks for tinyML." In it, he talks about how we can replace a combination of convolutional and pooling layers with a single convolutional layer with a stride of 2. The advantage of this is twofold: firstly, you get the same output size in both cases, but do not need to store the output of the convolutional layer which saves a lot of memory (1/4th less memory), and secondly you perform fewer computes so you get an increase in inference time as well. However, Pete also points out that this method might result in a drop in accuracy, but with the decrease in resource usage, you can regain that accuracy by changing some other hyperparameters of your model.
Pete’s trick reminded me of some convolutional neural network optimizations that I’ve studied myself, and in this article I would like to share them. In particular I want to dive a bit deeper into three things that Pete talks about: memory, pooling and computes. Let’s start with computes.