The Super Weight in Large Language Models
Authors: Mengxia Yu, De Wang, Qi Shan, Colorado Reed, Alvin Wan Paper: https://arxiv.org/abs/2411.07191 Code: https://github.com/mengxiayu/LLMSuperWeight
A fascinating study reveals that zeroing out a single weight inside an LLM can catastrophically degrade its performance. The authors call these critical parameters "super weights" and propose a method to find them in just one forward pass.
Trained LLMs contain a group of outlier weights with large magnitudes, comprising about 0.01% of all model weights - still hundreds of thousands in billion-parameter models. This was known before. The current work shows that within this group, there exists a single weight (the super weight, SW) - not necessarily the largest - whose importance exceeds the combined importance of thousands of other outliers. This weight is essential for quality; without it, LLMs cannot generate coherent text. Perplexity increases by several orders of magnitude, and zero-shot task accuracy drops to random when you zero it out.
Previously ( https://arxiv.org/abs/2402.17762), researchers discovered super-activations critical for model quality. These appear in various layers, have constant magnitude, and are consistently found in the same position regardless of input. The current work finds that the activation channel aligns with that of the super weight, with the activation first appearing immediately after the super weight. Pruning this super weight significantly reduces the activation, suggesting the activation is caused by it rather than merely correlated. These activations are called super activations ( SA).
Leave a Comment
Related Posts



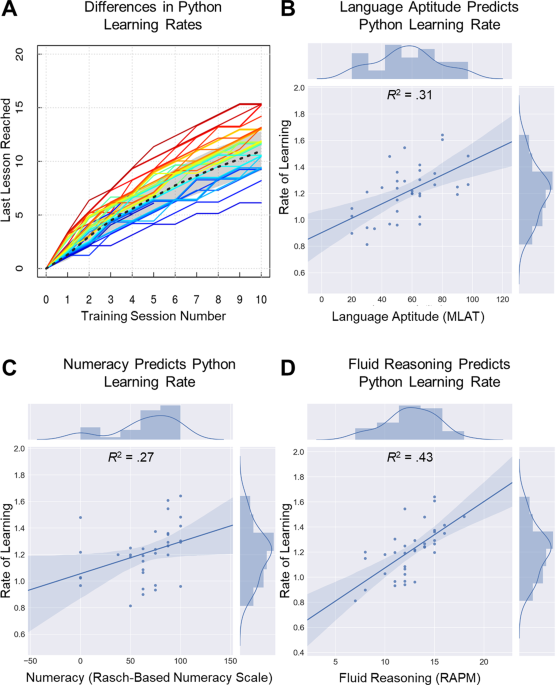
Relating Natural Language Aptitude to Individual Differences in Learning Programming Languages
Comment