chris-alexiuk/alpaca-lora
This repository contains code for reproducing the Stanford Alpaca results using low-rank adaptation (LoRA). We provide an Instruct model of similar quality to text-davinci-003 that can run on a Raspberry Pi (for research), and the code is easily extended to the 13b, 30b, and 65b models.
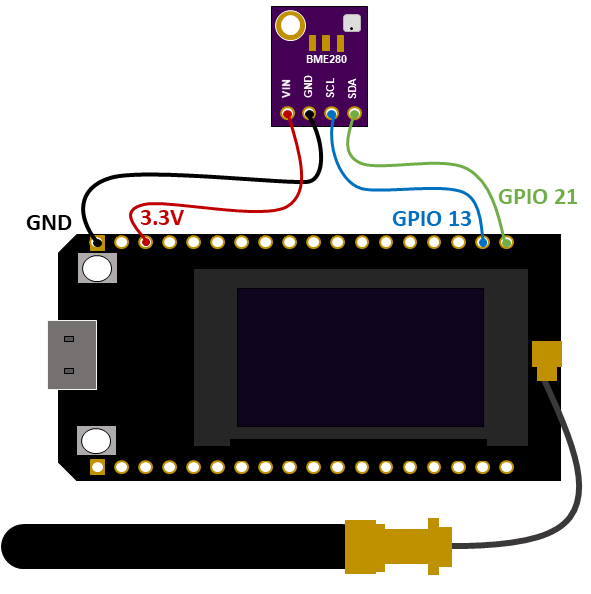
In addition to the training code, which runs within five hours on a single RTX 4090, we publish a script for downloading and inference on the foundation model and LoRA, as well as the resulting LoRA weights themselves. To fine-tune cheaply and efficiently, we use Hugging Face's PEFT as well as Tim Dettmers' bitsandbytes.
Without hyperparameter tuning, the LoRA model produces outputs comparable to the Stanford Alpaca model. (Please see the outputs included below.) Further tuning might be able to achieve better performance; I invite interested users to give it a try and report their results.
This file reads the foundation model from the Hugging Face model hub and the LoRA weights from tloen/alpaca-lora-7b, and runs a Gradio interface for inference on a specified input. Users should treat this as example code for the use of the model, and modify it as needed.









/cdn.vox-cdn.com/uploads/chorus_asset/file/24016887/STK093_Google_02.jpg)





