How to efficiently load data to memory
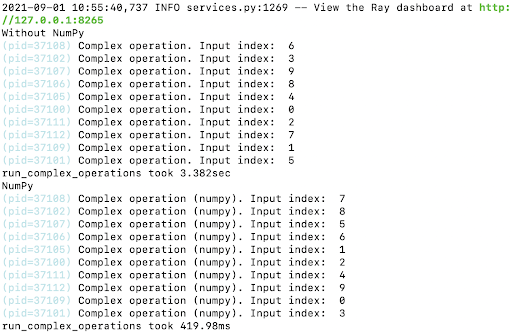
During the past months, we have been implementing “readers” and “writers” to a plenitude of data formats to Arrow in-memory format from scratch. To be specific, the formats that we covered were Apache Arrow IPC, Apache Parquet, Apache Avro, JSON, CSV and NDJSON. In all cases, the goal was to load them as fast as possible to a columnar in-memory format, which in this case was Apache Arrow (in Rust, see e.g. arrow2).
This post describes general observations we have been taking from this exercise. The core result presented here is that formats whose loading (IO-bound task) is explicitly separated from deserialization (CPU-bound task) are significantly faster to load to memory and allow for better resource utilization.
Loading data is a dreaded operation: everyone just wants to get over it and do the fun stuff with the data — a bit like “my code’s compiling”
Furthermore, loading is often the most important bottleneck in ETL and ML workloads. There are whole technological movements aimed at addressing this specific problem.