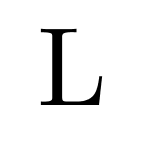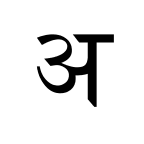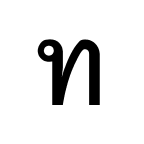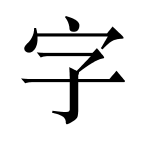Ridiculously fast unicode (UTF-8) validation
One of the most common “data type” in programming is the text string. When programmers think of a string, they imagine that they are dealing with a list or an array of characters. It is often a “good enough” approximation, but reality is more complex.
The characters must be encoded into bits in some way. Most strings on the Internet, including this blog post, are encoded using a standard called UTF-8. The UTF-8 format represents “characters” using 1, 2, 3 or 4 bytes. It is a generalization of the ASCII standard which uses just one byte per character. That is, an ASCII string is also an UTF-8 string.
It is slightly more complicated because, technically, what UTF-8 describes are code points, and a visible character, like emojis, can be made of several code points… but it is a pedantic distinction for most programmers.
There are other standards. Some older programming languages like C# and Java rely on UTF-16. In UTF-16, you use two or four bytes per character. It seemed like a good idea at the time, but I believe that the consensus is increasingly moving toward using UTF-8 all the time, everywhere.
Leave a Comment
Related Posts