Debate May Help AI Models Converge on Truth
An editorially independent publication supported by the Simons Foundation.
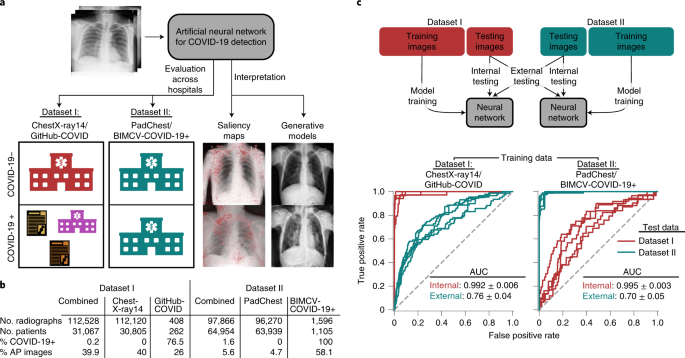
In February 2023, Google’s artificial intelligence chatbot Bard claimed that the James Webb Space Telescope had captured the first image of a planet outside our solar system. It hadn’t. When researchers from Purdue University asked OpenAI’s ChatGPT more than 500 programming questions, more than half of the responses were inaccurate.
These mistakes were easy to spot, but experts worry that as models grow larger and answer more complex questions, their expertise will eventually surpass that of most human users. If such “superhuman” systems come to be, how will we be able to trust what they say? “It’s about the problems you’re trying to solve being beyond your practical capacity,” said Julian Michael, a computer scientist at the Center for Data Science at New York University. “How do you supervise a system to successfully perform a task that you can’t?”
One possibility is as simple as it is outlandish: Let two large models debate the answer to a given question, with a simpler model (or a human) left to recognize the more accurate answer. In theory, the process allows the two agents to poke holes in each other’s arguments until the judge has enough information to discern the truth. The approach was first proposed six years ago, but two sets of findings released earlier this year — one in February from the AI startup Anthropic and the second in July from Google DeepMind — offer the first empirical evidence that debate between two LLMs helps a judge (human or machine) recognize the truth.