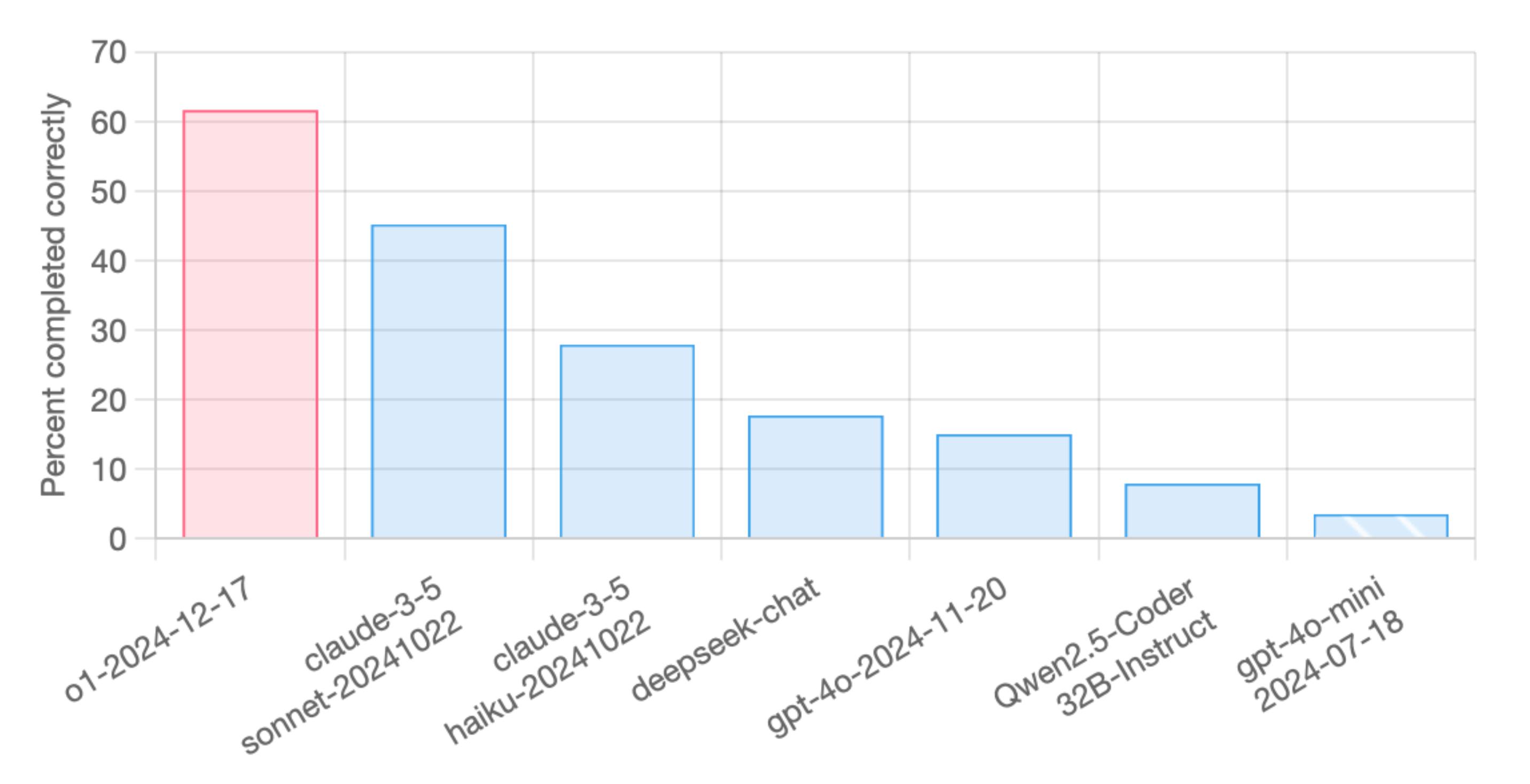
Semantic Video Chunking: Scene Detection
Just as RAG systems break down text documents into meaningful chunks for better processing and retrieval, video content benefits from intelligent segmentation through scene detection. This approach parallels text tokenization in several crucial ways:
Scene detection identifies natural boundaries in video content, maintaining semantic completeness just like how text chunking preserves sentence or paragraph integrity. Each scene represents a complete "thought" or action sequence, rather than arbitrary time-based splits. For example, in a cooking tutorial:
Scene-based chunks enable precise content retrieval. Instead of returning entire videos, systems can identify and serve the exact relevant scene, similar to how RAG systems return specific text passages rather than complete documents.
Unlike text tokenization, video scenes often contain multiple modalities (visual, audio, text-on-screen) that need to be processed together. This complexity makes intelligent chunking even more crucial for maintaining context and enabling accurate understanding.
Leave a Comment
Related Posts




Recent Posts


Giant sloths and mastodons lived with humans for millennia in the Americas, new discoveries suggest
Comment