How DoorDash leverages LLMs for better search retrieval
At DoorDash, users commonly conduct searches using precise queries that compound multiple requirements. As a result, our search system has to be flexible enough to generalize well to novel queries while also allowing us to enforce specific rules to ensure search result quality.
For instance, a query such as “vegan chicken sandwich,” for which a retrieval system that relies on document similarity — such as an embedding-based system — could retrieve documents (i.e., items) such as:
For these keywords only the last set on that list matches the user intent exactly. But preferences may vary for different attributes. For instance, a consumer might be open to considering any vegan sandwich as an alternative but would reject a chicken sandwich that is not vegan; dietary restrictions often take precedence over other attributes, like protein choices. Several approaches could be used to show users only the most relevant results. At DoorDash, we believe a flexible hybrid system is most likely to meet our needs; a keyword-based retrieval system, combined with robust document and keyword understanding, can effectively enforce such rules as ensuring that only vegan items are retrieved. Here, we will detail how we have used large language models, or LLMs, to improve our retrieval system and give consumers more accurate search results.
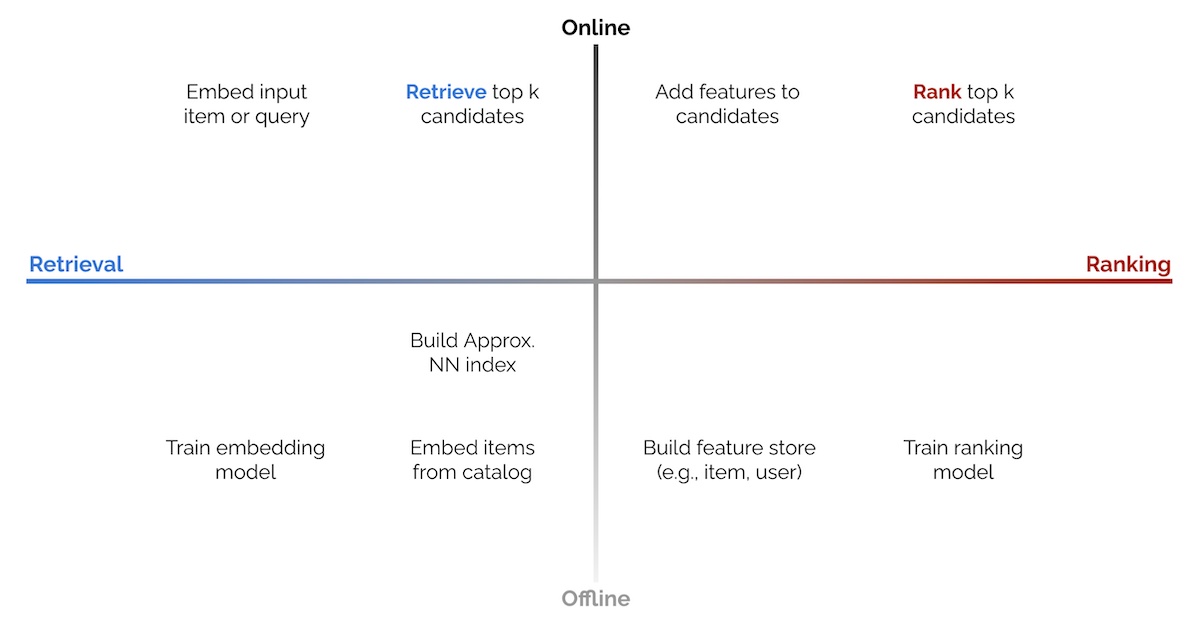
Typical search engines contain different stages, which can be separated into two main journeys: one for documents and another for queries. At DoorDash, documents refer to items or stores/restaurants, while queries are the search terms users enter into the search bar.