Data Branching for Batch Job Systems
Data is being increasingly treated like code has been treated for decades. For many use-cases it isn't enough to know "What is the current value?" but also "What was the value previously?", "Who last changed the value?", and "Why did they change the value?".
Having a history for data provides data security benefits by always being able to rollback to a previous value (and not just the last value, but any preceeding value). It provides an audit trail that can capture a lot more of the "Why" of data changes than purely "Person/System X changed the value at datetime Y". This can help with debuggability of data processes.
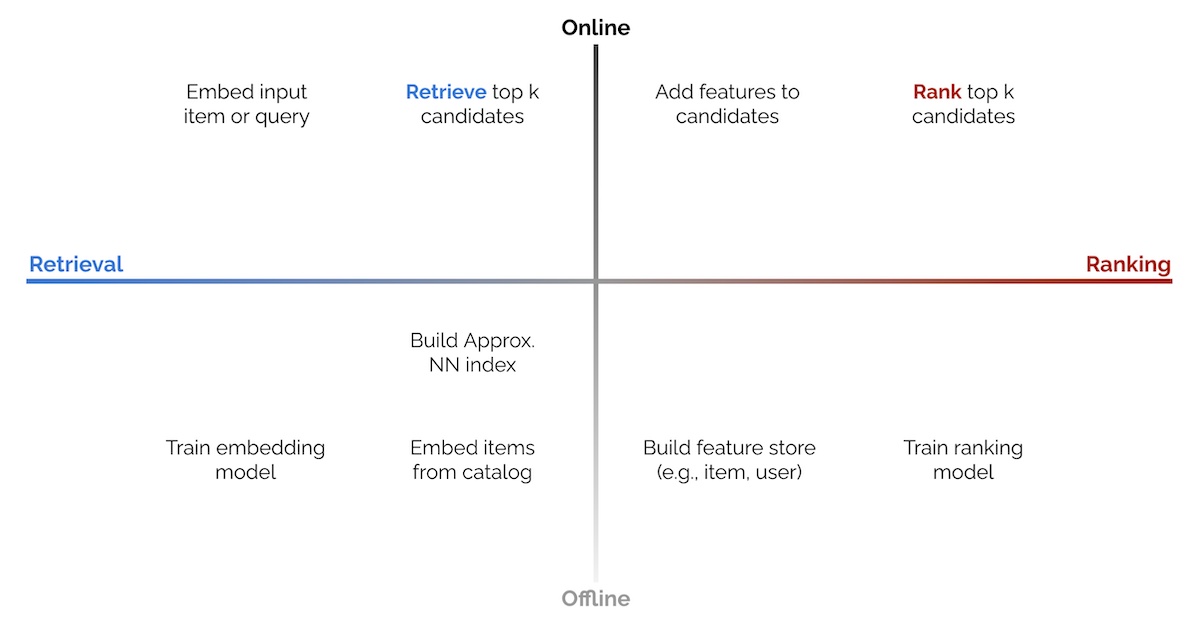
These benefits are behind the invention of tools such as lakeFS (2020) and Oxen.ai (2022). Both build out a Git-for-data system, involving the creation of data repositories, data branches, commits, merge commits, pull requests, etc. Planetscale has even been doing this for SQL databases. But how should these tools be used with a job-based batch data platform?
The "main" branch should be considered the canonical, production version of data. At the start of each job execution we can branch off this main branch and create a branch for our job execution.