
Scalable Web Scraping with Serverless - Part 1
Serverless computing offers a compelling solution by eliminating the need to manage infrastructure, allowing developers to focus solely on code. This model is perfect for web scraping tasks that vary in intensity and frequency, as it scales automatically to meet demand without any manual intervention. Moreover, serverless functions are cost-effective, as you only pay for the compute time you consume, making it an ideal choice for both small-scale projects and large-scale data extraction tasks.
In this blog series, we will explore how to leverage serverless technologies to build a robust and scalable web scraping infrastructure. We'll use a suite of AWS services including Lambda, S3, SQS, and RDS, combined with popular Node.js libraries like node-fetch for fetching data, cheerio for parsing HTML, and node-postgres to interact with databases.
Serverless computing is a cloud computing execution model where the cloud provider manages the setup, capacity planning, and server management for you. Essentially, it allows developers to write and deploy code without worrying about the underlying infrastructure. In a serverless setup, you only pay for the compute time you consume—there is no charge when your code is not running.
Leave a Comment
Related Posts




Recent Posts


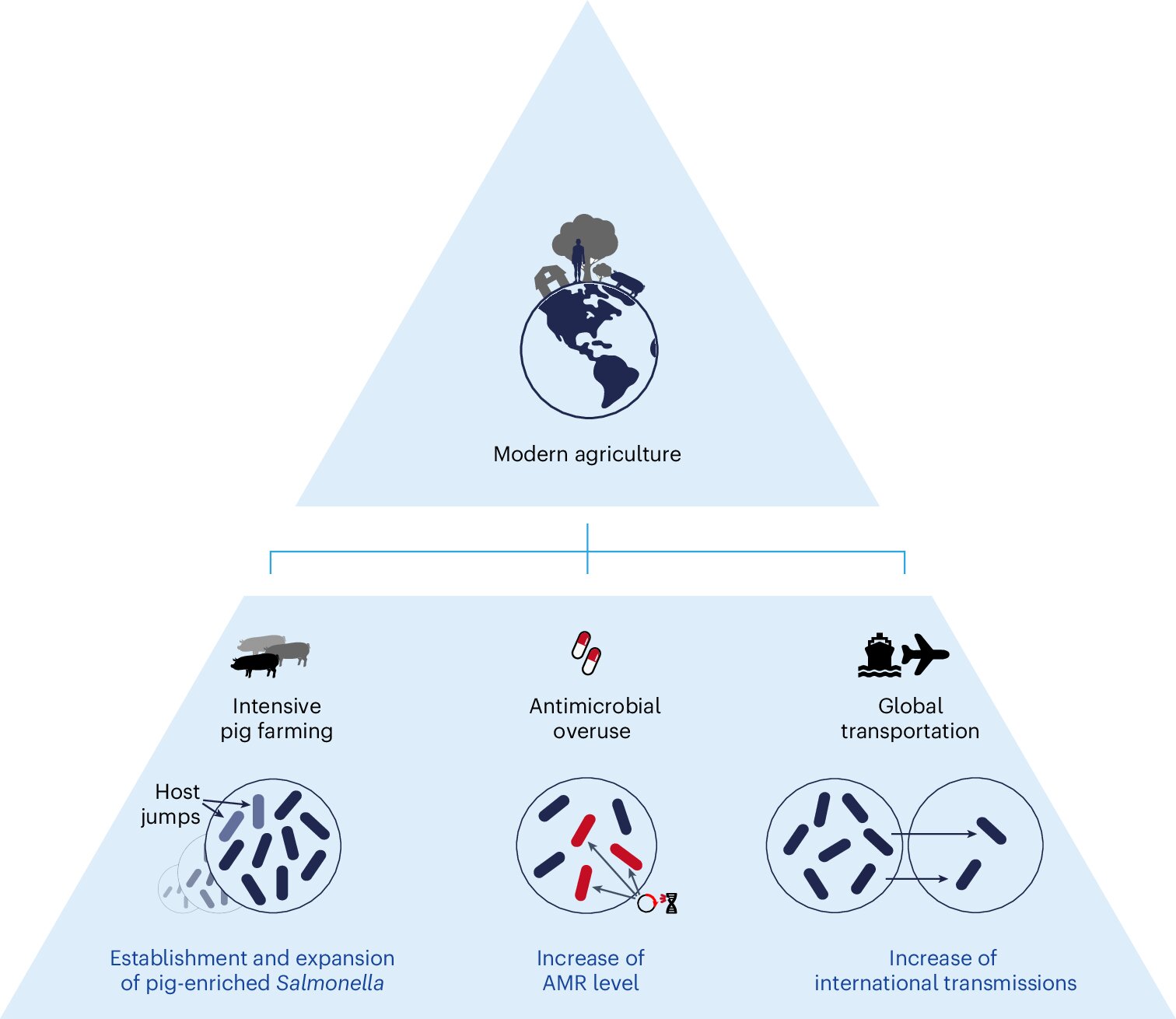
Changes in pig farming in the 20th century spread antibiotic-resistant Salmonella around the world, finds study
Comment





/cdn.vox-cdn.com/uploads/chorus_asset/file/25437708/2151307563.jpg)


