%20(1).png "Generalized Contrastive Learning for Multi-Modal Retrieval and Ranking")
Generalized Contrastive Learning for Multi-Modal Retrieval and Ranking
TL;DR We generalize the popular training method of CLIP to accommodate any number of text and images when representing documents and also encode relevance (or rank) to provide better first stage retrieval. Known as Generalized Contrastive Learning (GCL), our results show that GCL achieves a 94.5% increase in NDCG@10 and 504% for ERR@10 for in-domain and 26.3 - 48.8% and 44.3 - 108.0% increases in NDCG@10 and ERR@10 respectively for cold-start evaluations, measured relative to the CLIP baseline. When compared to a keyword search only baseline of BM25, there is an improvement of 300 - 750% for in-domain and cold start respectively across NDCG@10 and ERR@10. Finally we contribute a multi-modal benchmark dataset of 10M rows, across 100k queries and ~5M products each with ranking data for training and evaluation. Read more in the pre-print, GitHub repository, or below.
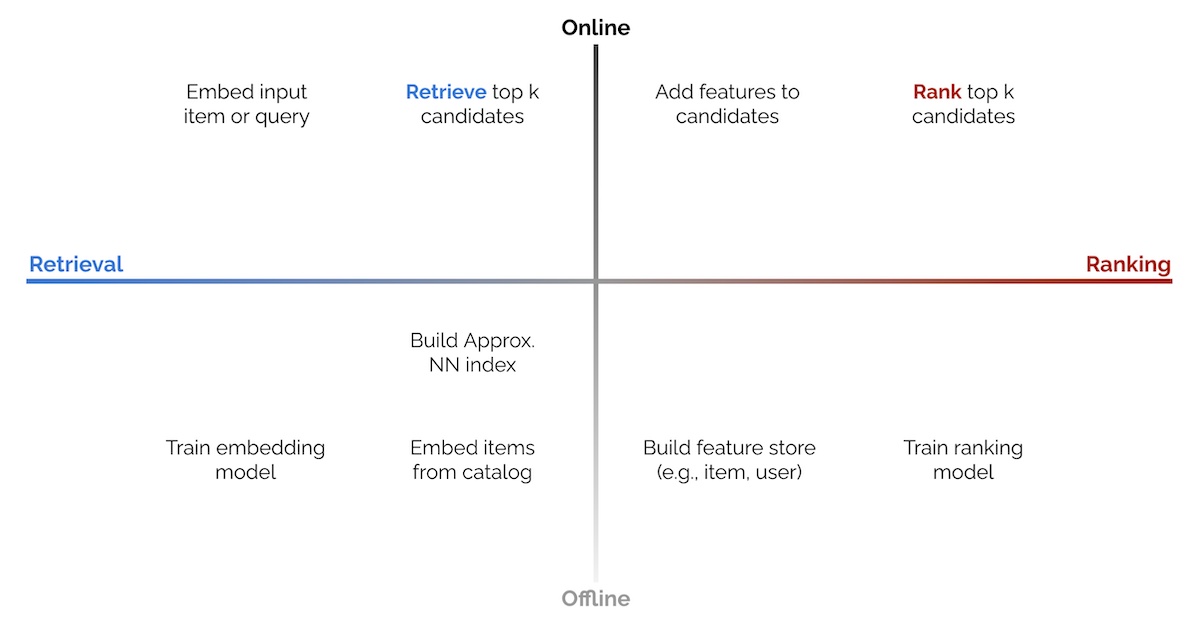
Vector search works by representing data as learned vectors - embeddings. Nearest neighbor search is then used to return the closest (i.e most relevant) results. The efficacy of the method relies on producing high quality embeddings. High quality embeddings are ones that have the desired similarity accurately encoded in the underlying vector space - things that are close together in the vector space are “relevant” in the downstream application. However, real-world use cases are more complex than single document, single query schemes with embedding models trained on binary relevance relationships.















/cdn.vox-cdn.com/uploads/chorus_asset/file/25440969/videoframe_48666.png)





