Tracking source locations
Futhark is a programming language meant for writing fast programs, but as is the case for every programming language meant for writing fast programs, it inevitably happens that a programmer will use it to write a program that is not fast. When this happens, the programmer will likely want to know why their program is not fast, and how to make it faster. A useful tool for answering such questions is a profiler - a tool that tells you how long the different parts of your program take to run. This post is about how profiling in Futhark became slightly more useful with the most recent release.
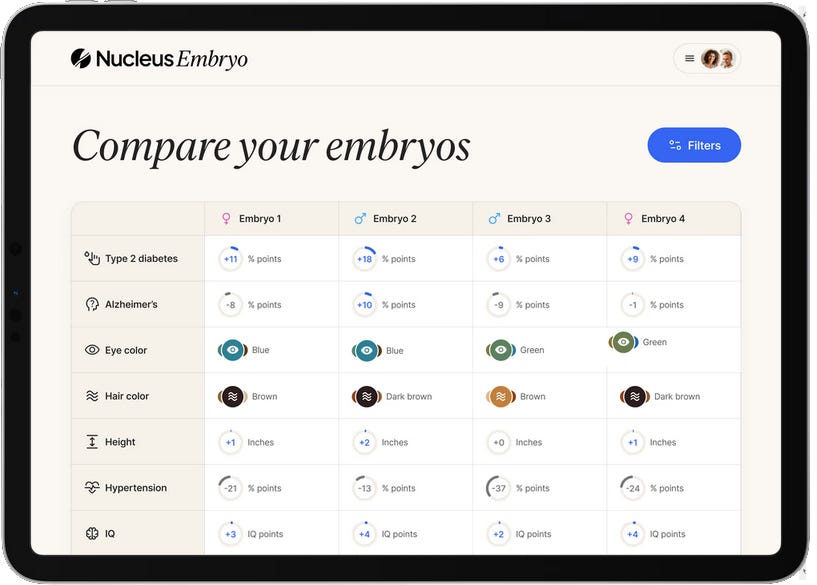
Initially, Futhark had no real profiling support, except for some semi-documented support for dumping a report of GPU operations. Eventually we added futhark profile, which allows the machine-readable profiling data produced by futhark bench to be turned into human-readable reports. Specifically, the Futhark runtime system will tally up the time spent in various cost centres, which for the GPU backends are GPU kernels and other operations such as copies, and put it in a table. However, the information you get out still looks like this:
Now a user may reasonable object: “Hold on! I don’t remember my program containing anything called main.segmap_23494!” And indeed, these cost centres refer to compiler-generated names. You can squint to get some meaning out of them: segscan is certainly some kind of scan operation, and segmap is a map. But due to inlining, it can be difficult to guess which functions result in which GPU operations, and optimisations may obscure the relation between source code and generated code - indeed, those segmap_intrablock operations are actually mainly (nested) scans that are then turned into block-level scans via incremental flattening. But clearly it is still not easy to use this information. The profiler will usually just tell the programmer that their program spends all its time executing code with a name the programmer cannot possibly recognise. What is missing is a way to relate generated code with the original source code. I decided to call such information provenance, in the sense of “the ultimate origin of something”. The problem is then to attach provenance to every bit of generated code, and in particular, to the generated GPU kernels.