Search code, repositories, users, issues, pull requests...
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
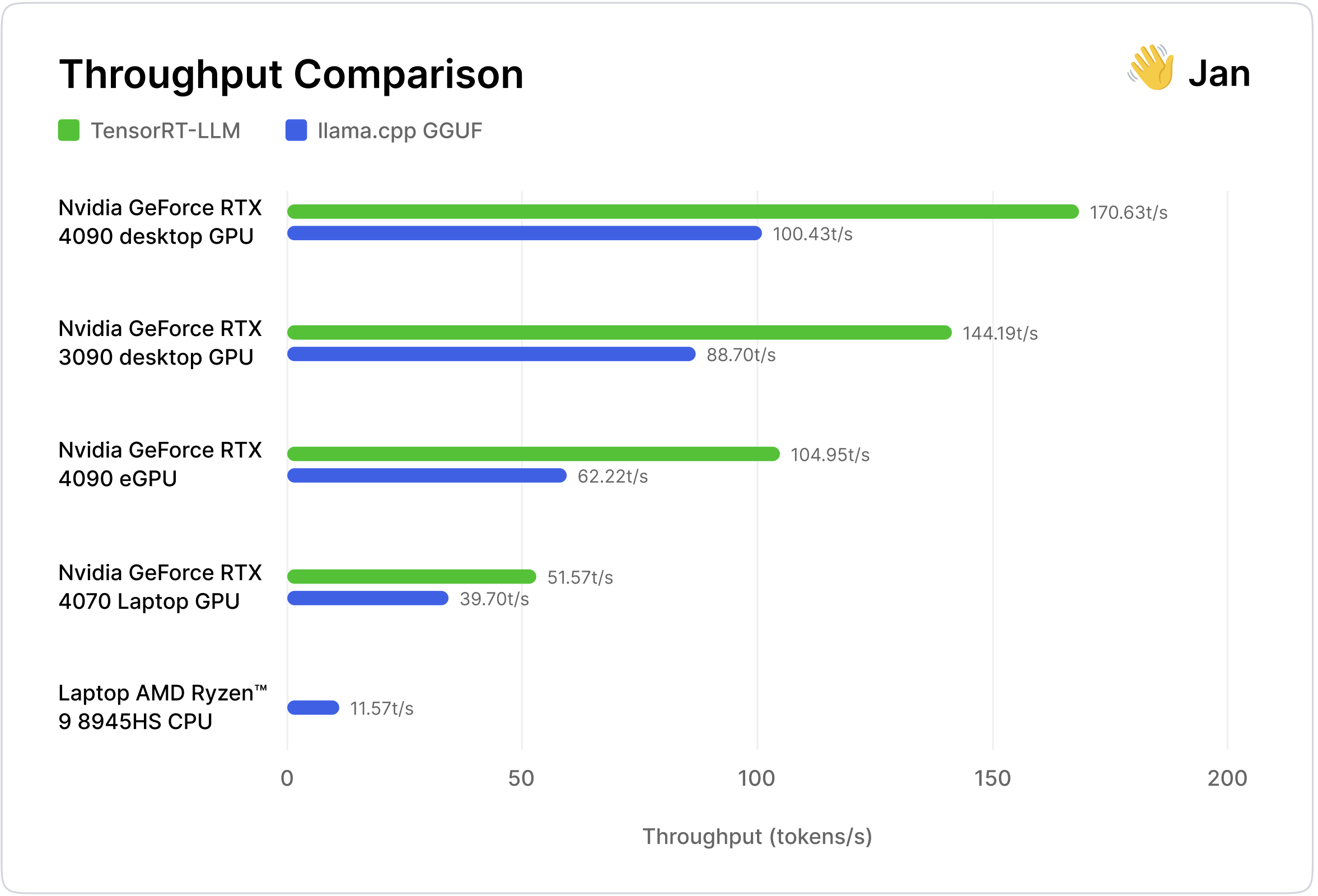
This change upstreams llamafile's cpu matrix multiplication kernels which improve image and prompt evaluation speed. For starters, Q4_0 and Q8_0 weights should go ~40% faster on CPU. The biggest benefits are with data types like f16 / f32, which process prompts 2x faster thus making them faster than quantized data types for prompt evals.
This change also introduces bona fide AVX512 support since tinyBLAS is able to exploit the larger register file. For example, on my CPU llama.cpp llava-cli processes an image prompt at 305 tokens/second, using the Q4_K and Q4_0 types, which has always been faster than if we used f16 LLaVA weights, which at HEAD go 188 tokens/second. With this change, f16 LLaVA performance leap frogs to 464 tokens/second.
On Intel Core i9-14900K this change improves F16 prompt perf by 5x. For example, using llama.cpp at HEAD with Mistral 7b f16 to process a 215 token prompt will go 13 tok/sec. This change has fixes making it go 52 tok/sec. It's mostly thanks to my vectorized outer product kernels but also because I added support for correctly counting the number of cores on Alderlake, so the default thread count discounts Intel's new efficiency cores. Only Linux right now can count cores.
Leave a Comment



Recent Posts


SatBird: a Dataset for Bird Species Distribution Modeling using Remote Sensing and Citizen Science Data
Comment
Dolphin Emulator - Dolphin Progress Report Tenth Anniversary Special: February, March, and April 2024
Comment

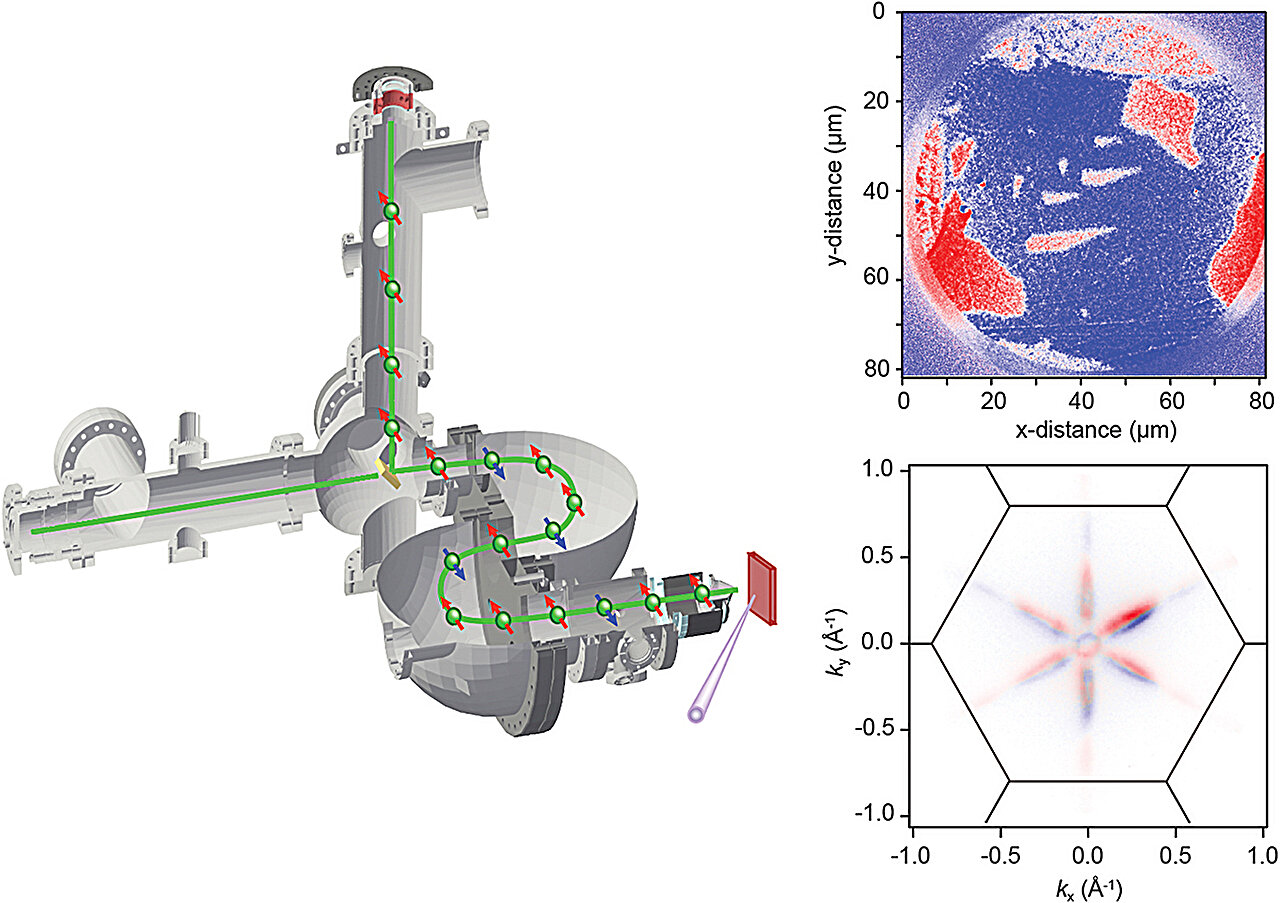
A new spin on materials analysis: Benefits of probing electron spin states at much higher resolution and efficiency
Comment